Around late June, the social media platform Reddit made a small but significant change in its fight against bots – AI scraping bots in particular.
The change was to Reddit’s robots.txt file, a file that implements the Robots Exclusion Protocol standard. Websites use robots.txt files to define rules that bots must – or rather, ought to – follow. Rules can be used to prohibit bots from accessing certain areas of a website, or to prohibit certain bots, such as Googlebot, completely. However, it’s up to the bot whether it chooses to respect the rules it finds within robots.txt – if it even bothers to read the file at all. Google’s bots, such as its main scraper, Googlebot, naturally respect robots.txt. Less discerning bot operators have little motivation to obey robots.txt rules, however, and entirely malicious bots essentially never do.
Nevertheless, the vast majority of major websites use robots.txt files to tell bots which parts of the website they may crawl – and most (good) bots will respect the rules they find therein.
Prior to late June, the Reddit robots.txt resembled that of any other large social media platform. This archived version from 5 June, courtesy of Archive.org – which has recently come under orchestrated cyberattack – is exactly as would be expected. Certain bots, such as that belonging to 80legs, a cloud-based web scraper that has attracted criticism for hammering websites so frequently it amounts to a DDoS attack, are prohibited from accessing any area of Reddit. Certain sensitive paths are disallowed for all bots: such as /login and /*.json, and error pages and RSS feeds. All of this is normal and expected.
On 24 June, Reddit’s admins quietly announced an update to Reddit’s robots.txt and few people took notice.
The current robots.txt now resembles:
# Welcome to Reddit's robots.txt
# Reddit believes in an open internet, but not the misuse of public content.
# See https://support.reddithelp.com/hc/en-us/articles/26410290525844-Public-Content-Policy Reddit's Public Content Policy for access and use restrictions to Reddit content.
# See https://www.reddit.com/r/reddit4researchers/ for details on how Reddit continues to support research and non-commercial use.
# policy: https://support.reddithelp.com/hc/en-us/articles/26410290525844-Public-Content-Policy
User-agent: *
Disallow: /The asterisk is a wildcard, matching all bots. The forward slash is Reddit’s root directory. This means, as of 24 June 2024, that every bot is prohibited from scraping any part of Reddit. No bot is allowed to access any part of the social media giant’s website.
The changes were announced by Reddit account /u/traceroo – the handle used by Ben Lee, Reddit’s Chief Legal Officer who joined the company in 2019 and reports directly to CEO Steve Huffman. Lee explained the reasoning:
Way back in the early days of the internet, most websites implemented the Robots Exclusion Protocol (aka our robots.txt file), to share high-level instructions about how a site wants to be crawled by search engines. It is a completely voluntary protocol (though some bad actors just ignore the file) and was never meant to provide clear guardrails, even for search engines, on how that data could be used once it was accessed.
Unfortunately, we’ve seen an uptick in obviously commercial entities who scrape Reddit and argue that they are not bound by our terms or policies. Worse, they hide behind robots.txt and say that they can use Reddit content for any use case they want. While we will continue to do what we can to find and proactively block these bad actors, we need to do more to protect Redditors’ contributions.
Lee further explained that, in order for a bot to gain access to Reddit, operators should reach out to the company.
In the next few weeks, we’ll be updating our robots.txt instructions to be as clear as possible: if you are using an automated agent to access Reddit, you need to abide by our terms and policies, and you need to talk to us. We believe in the open internet, but we do not believe in the misuse of public content.
Bots belonging to the Internet Archive, who provide archival of online content through their Wayback Machine service at Archive.org, were explicitly allowed to continue to crawl Reddit. As of November, it remains unknown if other bots have been similarly whitelisted.
Many commentators expressed skepticism shortly after the move, with some decrying it as a cynical money-making initiative. Only months prior, Reddit struck a $60 million per year deal with Google, allowing Google to use Reddit users’ public content to train AI.
On the platform, user reactions varied. Some users responded with confusion, wondering how Reddit could possibly benefit from harming its appearance in search engines.
One user, /u/domstersch, described the change as an example of ‘enshittification‘ – the slow decline in quality of online platforms and services.
Make no mistake, this is enshittification, just as much as the API changes were. Scraping against the wishes of the scraped is good, actually.
This is indeed about “how to best protect Reddit” (Inc.), not it’s users or our content, so you may as well drop the disingenuous framing and say it like it is: you want to constrain competition by increasing switching costs as much as you can. Within your legal rights? Sure! Still enshittifying? Absolutely.
The Reddit admin replied to encourage archivists, journalists and data scientists to visit the /r/data4researchers subreddit, and highlighted their public API, which he said is open for non-commercial access.
Elsewhere, some were more understanding of the move, broadly accepting Reddit’s reasoning – particularly against a backdrop of increasingly data-hungry AI bots unleashed on the Internet to harvest all they can find.
However, when we tested Reddit’s robots.txt using Google’s Rich Results Test, it appears Reddit is showing the outdated version to Google.
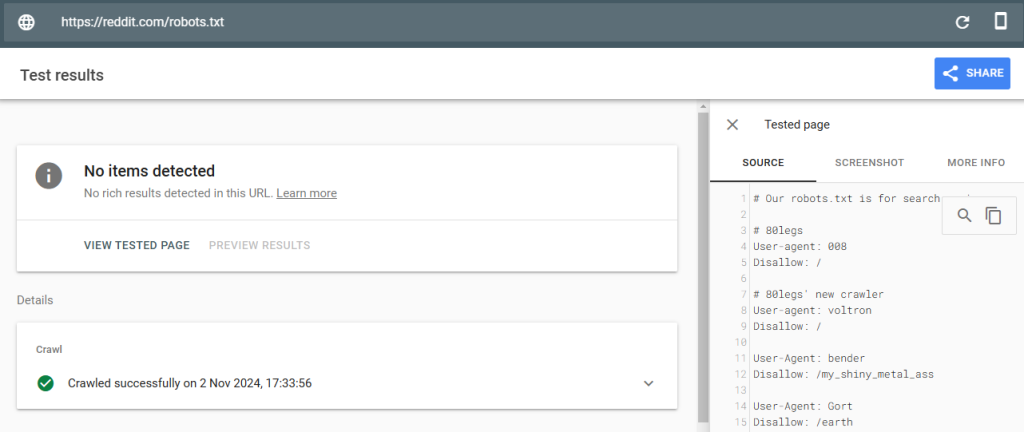
This suggests that Reddit is showing a different version of the file to search engine bots, and raises the possibility that the move was more of a public exposition of their frustration with AI bots – or a scare tactic to encourage bot developers to pay up or soon lose access, without risking actual damage to Reddit’s visibility in search results.
Circuit Bulletin reached out to Reddit for comment, but were directed to Reddit’s official announcement in June.
(Attribution: main graphic based on modified original by Seobility. License: CC BY-SA 4.0.)


